![]()
Certification Topics of SAA-C03 Exam PDF Recently Updated Questions
SAA-C03 Exam Prep Guide: Prep guide for the SAA-C03 Exam
Amazon SAA-C03 certification exam is intended for solutions architects, systems administrators, and developers who have experience in designing and deploying cloud-based solutions. SAA-C03 exam covers a wide range of topics, including AWS architecture, storage, compute, networking, security, and more. It also covers best practices for designing solutions on AWS and how to optimize performance and cost.
Passing the Amazon SAA-C03 certification exam requires a deep understanding of AWS services, architectures, and best practices. SAA-C03 exam tests the candidate’s ability to design, deploy, and manage scalable, highly available, and fault-tolerant systems on AWS. In addition, the exam also tests the candidate’s knowledge of security, migration, and cost optimization on AWS.
Amazon SAA-C03 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
NEW QUESTION # 461
A company recently migrated its web application to the AWS Cloud The company uses an Amazon EC2 instance to run multiple processes to host the application. The processes include an Apache web server that serves static content The Apache web server makes requests to a PHP application that uses a local Redis server for user sessions.
The company wants to redesign the architecture to be highly available and to use AWS managed solutions Which solution will meet these requirements?
- A. Configure an Amazon CloudFront distribution with an Amazon S3 endpoint to an S3 bucket that is configured to host the static content. Configure an Application Load Balancer that targets an Amazon Elastic Container Service (Amazon ECS) service that runs AWS Fargate tasks for the PHP application. Configure the PHP application to use an Amazon ElastiCache for Redis cluster that runs in multiple Availability Zones
- B. Use AWS Lambda to host the static content and the PHP application. Use an Amazon API Gateway REST API to proxy requests to the Lambda function. Set the API Gateway CORS configuration to respond to the domain name. Configure Amazon ElastiCache for Redis to handle session information
- C. Keep the backend code on the EC2 instance. Create an Amazon ElastiCache for Redis cluster that has Multi-AZ enabled Configure the ElastiCache for Redis cluster in cluster mode Copy the frontend resources to Amazon S3 Configure the backend code to reference the EC2 instance
- D. Use AWS Elastic Beanstalk to host the static content and the PHP application. Configure Elastic Beanstalk to deploy its EC2 instance into a public subnet Assign a public IP address.
Answer: A
Explanation:
Understanding the Requirement: The company needs to redesign the architecture to be highly available and use AWS managed solutions for hosting a web application with static content, PHP application, and Redis for user sessions.
Analysis of Options:
AWS Elastic Beanstalk: Suitable for simplifying deployment but may not provide the desired flexibility and control for complex architectures.
AWS Lambda and API Gateway: Not ideal for hosting a stateful PHP application and handling static content. Adding complexity without significant benefit.
EC2 instance with ElastiCache and S3: Provides some high availability but involves managing EC2 instances, which increases operational overhead.
CloudFront with S3, ALB, ECS with Fargate, and ElastiCache: This solution leverages fully managed AWS services for each component, ensuring high availability and scalability.
Best Solution:
CloudFront with S3, ALB, ECS with Fargate, and ElastiCache: This combination of services meets the requirements for a highly available and managed solution, ensuring optimal performance and minimal operational overhead.
Reference:
Amazon CloudFront
Amazon S3
Amazon ECS with Fargate
Amazon ElastiCache for Redis
NEW QUESTION # 462
[Design Secure Architectures]
A company wants to provide a third-party system that runs in a private data center with access to its AWS account. The company wants to call AWS APIs directly from the third-party system. The company has an existing process for managing digital certificates. The company does not want to use SAML or OpenID Connect (OIDC) capabilities and does not want to store long-term AWS credentials.
Which solution will meet these requirements?
- A. Configure Kerberos to exchange tickets for assertions that can be validated by AWS APIs.
- B. Configure AWS Signature Version 4 to authenticate incoming HTTPS requests to AWS APIs.
- C. Configure mutual TLS to allow authentication of the client and server sides of the communication channel.
- D. Configure AWS Identity and Access Management (IAM) Roles Anywhere to exchange X.509 certificates for AWS credentials to interact with AWS APIs.
Answer: D
Explanation:
A . Mutual TLS:Provides secure communication but does not integrate with AWS credential exchange.
B . AWS Signature v4:Requires direct integration with AWS and is less secure for external systems.
C . Kerberos:Not natively supported for AWS API authentication.
D . IAM Roles Anywhere:Enables AWS API access using X.509 certificates without long-term credentials.
NEW QUESTION # 463
[Design Secure Architectures]
A developer is creating an ecommerce workflow in an AWS Step Functions state machine that includes an HTTP Task state. The task passes shipping information and order details to an endpoint.
The developer needs to test the workflow to confirm that the HTTP headers and body are correct and that the responses meet expectations.
Which solution will meet these requirements?
- A. Use the TestState API to invoke the state machine. Set the inspection level to DEBUG.
- B. Use the TestState API to invoke only the HTTP Task. Set the inspection level to TRACE.
- C. Change the log level of the state machine to ALL. Run the state machine.
- D. Use the data flow simulator to invoke only the HTTP Task. View the request and response data.
Answer: C
Explanation:
State Machine Testing with Logs:
Changing the log level to ALL enables capturing detailed request and response data. This helps verify HTTP headers, body, and responses.
Incorrect Options Analysis:
Option A and B: The TestState API is not a valid option for Step Functions.
Option C: A data flow simulator does not exist for AWS Step Functions.
Reference:
Step Functions Logging and Monitoring
NEW QUESTION # 464
A company is running a microservices application on Amazon EC2 instances. The company wants to migrate the application to an Amazon Elastic Kubernetes Service (Amazon EKS) cluster for scalability. The company must configure the Amazon EKS control plane with endpoint private access set to true and endpoint public access set to false to maintain security compliance The company must also put the data plane in private subnets. However, the company has received error notifications because the node cannot join the cluster.
Which solution will allow the node to join the cluster?
- A. Create interface VPC endpoints to allow nodes to access the control plane.
- B. Allow outbound traffic in the security group of the nodes.
- C. Grant the required permission in AWS Identity and Access Management (IAM) to the AmazonEKSNodeRole IAM role.
- D. Recreate nodes in the public subnet Restrict security groups for EC2 nodes
Answer: A
Explanation:
Kubernetes API requests within your cluster's VPC (such as node to control plane communication) use the private VPC endpoint.https://docs.aws.amazon.com/eks/latest/userguide/cluster-endpoint.html
NEW QUESTION # 465
A solutions architect must develop an automated solution to identify objects that contain PII and apply the necessary controls to prevent deletion before review.
Which combination of steps should the solutions architect take to meet these requirements? (Select THREE.)
- A. Create an Amazon EventBridge rule that invokes the AWS Lambda function when Amazon Macie detects sensitive data.
- B. Create an AWS Lambda function that performs an S3 Object Lock legal hold operation on the identified objects.
- C. Create a job in Amazon Macie to scan the S3 buckets for the relevant sensitive data identifiers.
- D. Create an AWS Lambda function that applies an S3 Object Lock retention period to the identified objects in governance mode.
- E. Move the identified objects to the S3 Glacier Deep Archive storage class.
- F. Configure multi-factor authentication (MFA) delete on the S3 buckets.
Answer: A,B,C
Explanation:
* A: Amazon Macie can scan S3 buckets for sensitive data and identify PII.
* C: S3 Object Lock legal hold prevents object deletion until a review is complete, meeting compliance requirements.
* E: EventBridge can trigger the Lambda function automatically when Macie detects sensitive data, creating an automated workflow.
AWS Documentation Extract:
"Amazon Macie automatically discovers, classifies, and protects sensitive data in AWS. You can use EventBridge to invoke a Lambda function for post-processing, such as applying Object Lock legal hold to flagged objects." (Source: AWS Macie and S3 Object Lock documentation)
* B, D: Moving to Glacier Deep Archive or applying retention in governance mode is not specific to deletion prevention pending review.
* F: MFA Delete adds a security layer but does not automate object retention for flagged PII.
Reference: AWS Certified Solutions Architect - Official Study Guide, S3 Compliance and Data Protection.
NEW QUESTION # 466
An online photo-sharing company stores Hs photos in an Amazon S3 bucket that exists in the us-west-1 Region. The company needs to store a copy of all new photos in the us-east-1 Region.
Which solution will meet this requirement with the LEAST operational effort?
- A. Create a second S3 bucket in us-east-1. Use S3 Cross-Region Replication to copy photos from the existing S3 bucket to the second S3 bucket.
- B. Create a second S3 bucket In us-east-1. Configure S3 event notifications on object creation and update events to Invoke an AWS Lambda function to copy photos from the existing S3 bucket to the second S3 bucket.
- C. Create a second S3 bucket in us-east-1 across multiple Availability Zones. Create an S3 Lifecycle rule to save photos into the second S3 bucket,
- D. Create a cross-origin resource sharing (CORS) configuration of the existing S3 bucket. Specify us-east-1 in the CORS rule's AllowedOngm element.
Answer: A
Explanation:
Understanding the Requirement: The company needs to store a copy of all new photos in the us-east-1 Region from an S3 bucket in the us-west-1 Region.
Analysis of Options:
Cross-Region Replication: Automatically replicates objects across regions with minimal operational effort once configured.
CORS Configuration: Used for allowing resources on a web page to be requested from another domain, not for replication.
S3 Lifecycle Rule: Manages the transition of objects between storage classes within the same bucket, not for cross-region replication.
S3 Event Notifications with Lambda: Requires additional configuration and management compared to Cross-Region Replication.
Best Solution:
S3 Cross-Region Replication: This solution provides an automated and efficient way to replicate objects to another region, meeting the requirement with the least operational effort.
Reference:
Amazon S3 Cross-Region Replication
NEW QUESTION # 467
[Design Secure Architectures]
A company wants to use artificial intelligence (Al) to determine the quality of its customer service calls. The company currently manages calls in four different languages, including English. The company will offer new languages in the future. The company does not have the resources to regularly maintain machine learning (ML) models.
The company needs to create written sentiment analysis reports from the customer service call recordings. The customer service call recording text must be translated into English.
Which combination of steps will meet these requirements? (Select THREE.)
- A. Use Amazon Translate to translate text in any language to English.
- B. Use Amazon Comprehend to create the sentiment analysis reports.
- C. Use Amazon Lex to create the written sentiment analysis reports.
- D. Use Amazon Polly to convert the audio recordings into text.
- E. Use Amazon Transcribe to convert the audio recordings in any language into text.
- F. Use Amazon Comprehend to translate the audio recordings into English.
Answer: A,B,E
Explanation:
These answers are correct because they meet the requirements of creating written sentiment analysis reports from the customer service call recordings in any language and translating them into English. Amazon Transcribe is a service that uses advanced machine learning technologies to recognize speech in audio files and transcribe them into text. You can use Amazon Transcribe to convert the audio recordings in any language into text, and specify the language code of the source audio. Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation. You can use Amazon Translate to translate text in any language to English, and specify the source and target language codes. Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. You can use Amazon Comprehend to create the sentiment analysis reports, which determine if the text is positive, negative, neutral, or mixed.
Reference:
https://docs.aws.amazon.com/transcribe/latest/dg/what-is-transcribe.html
https://docs.aws.amazon.com/translate/latest/dg/what-is.html
https://docs.aws.amazon.com/comprehend/latest/dg/how-sentiment.html
NEW QUESTION # 468
A company uses an organization in AWS Organizations to manage AWS accounts that contain applications. The company sets up a dedicated monitoring member account in the organization. The company wants to query and visualize observability data across the accounts by using Amazon CloudWatch.
Which solution will meet these requirements?
- A. Configure a new 1AM user in the monitoring account. In each AWS account, configure an 1AM policy to have access to query and visualize the CloudWatch data in the account. Attach the new 1AM policy to the new I AM user.
- B. Enable CloudWatch cross-account observability for the monitoring account. Deploy an AWS CloudFormation template provided by the monitoring account in each AWS account to share the data with the monitoring account.
- C. Create a new 1AM user in the monitoring account. Create cross-account 1AM policies in each AWS account. Attach the 1AM policies to the new 1AM user.
- D. Set up service control policies (SCPs) to provide access to CloudWatch in the monitoring account under the Organizations root organizational unit (OU).
Answer: B
Explanation:
CloudWatch cross-account observability is a feature that allows you to monitor and troubleshoot applications that span multiple accounts within a Region. You can seamlessly search, visualize, and analyze your metrics, logs, traces, and Application Insights applications in any of the linked accounts without account boundaries1. To enable CloudWatch cross-account observability, you need to set up one or more AWS accounts as monitoring accounts and link them with multiple source accounts. A monitoring account is a central AWS account that can view and interact with observability data shared by other accounts. A source account is an individual AWS account that shares observability data and resources with one or more monitoring accounts1. To create links between monitoring accounts and source accounts, you can use the CloudWatch console, the AWS CLI, or the AWS API. You can also use AWS Organizations to link accounts in an organization or organizational unit to the monitoring account1. CloudWatch provides a CloudFormation template that you can deploy in each source account to share observability data with the monitoring account. The template creates a sink resource in the monitoring account and an observability link resource in the source account. The template also creates the necessary IAM roles and policies to allow cross-account access to the observability data2. Therefore, the solution that meets the requirements of the question is to enable CloudWatch cross-account observability for the monitoring account and deploy the CloudFormation template provided by the monitoring account in each AWS account to share the data with the monitoring account.
The other options are not valid because:
Service control policies (SCPs) are a type of organization policy that you can use to manage permissions in your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization, allowing you to ensure your accounts stay within your organization's access control guidelines3. SCPs do not provide access to CloudWatch in the monitoring account, but rather restrict the actions that users and roles can perform in the source accounts. SCPs are not required to enable CloudWatch cross-account observability, as the CloudFormation template creates the necessary IAM roles and policies for cross-account access2.
IAM users are entities that you create in AWS to represent the people or applications that use them to interact with AWS. IAM users can have permissions to access the resources in your AWS account4. Configuring a new IAM user in the monitoring account and an IAM policy in each AWS account to have access to query and visualize the CloudWatch data in the account is not a valid solution, as it does not enable CloudWatch cross-account observability. This solution would require the IAM user to switch between different accounts to view the observability data, which is not seamless and efficient. Moreover, this solution would not allow the IAM user to search, visualize, and analyze metrics, logs, traces, and Application Insights applications across multiple accounts in a single place1.
Cross-account IAM policies are policies that allow you to delegate access to resources that are in different AWS accounts that you own. You attach a cross-account policy to a user or group in one account, and then specify which accounts the user or group can access5. Creating a new IAM user in the monitoring account and cross-account IAM policies in each AWS account is not a valid solution, as it does not enable CloudWatch cross-account observability. This solution would also require the IAM user to switch between different accounts to view the observability data, which is not seamless and efficient. Moreover, this solution would not allow the IAM user to search, visualize, and analyze metrics, logs, traces, and Application Insights applications across multiple accounts in a single place1.
NEW QUESTION # 469
A company wants to move its application to a serverless solution. The serverless solution needs to analyze existing and new data by using SL. The company stores the data in an Amazon S3 bucket. The data requires encryption and must be replicated to a different AWS Region.
Which solution will meet these requirements with the LEAST operational overhead?
- A. Create a new S3 bucket. Load the data into the new S3 bucket. Use S3 Cross-Region Replication (CRR) to replicate encrypted objects to an S3 bucket in another Region. Use server-side encryption with AWS KMS multi-Region kays (SSE-KMS). Use Amazon Athena to query the data.
- B. Load the data into the existing S3 bucket. Use S3 Cross-Region Replication (CRR) to replicate encrypted objects to an S3 bucket in another Region. Use server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Use Amazon Athena to query the data.
- C. Create a new S3 bucket. Load the data into the new S3 bucket. Use S3 Cross-Region Replication (CRR) to replicate encrypted objects to an S3 bucket in another Region. Use server-side encryption with AWS KMS multi-Region keys (SSE-KMS). Use Amazon RDS to query the data.
- D. Load the data into the existing S3 bucket. Use S3 Cross-Region Replication (CRR) to replicate encrypted objects to an S3 bucket in another Region. Use server-side encryption with Amazon S3 managed encryption keys (SSE-S3). Use Amazon RDS to query the data.
Answer: A
NEW QUESTION # 470
A company has an AWS Glue extract. transform, and load (ETL) job that runs every day at the same time. The job processes XML data that is in an Amazon S3 bucket.
New data is added to the S3 bucket every day. A solutions architect notices that AWS Glue is processing all the data during each run.
What should the solutions architect do to prevent AWS Glue from reprocessing old data?
- A. Use a FindMatches machine learning (ML) transform.
- B. Edit the job by setting the NumberOfWorkers field to 1.
- C. Edit the job to delete data after the data is processed
- D. Edit the job to use job bookmarks.
Answer: D
NEW QUESTION # 471
A company has launched an Amazon RDS for MySQL DB instance. Most of the connections to the database come from serverless applications. Application traffic to the database changes significantly at random intervals. At times of high demand, users report that their applications experience database connection rejection errors.
Which solution will resolve this issue with the LEAST operational overhead?
- A. Deploy Amazon ElastiCache (Memcached) between the users' applications and the DB instance.
- B. Migrate the DB instance to a different instance class that has higher I/O capacity. Configure the users' applications to use the new DB instance.
- C. Configure Multi-AZ for the DB instance. Configure the users' applications to switch between the DB instances.
- D. Create a proxy in RDS Proxy. Configure the users' applications to use the DB instance through RDS Proxy.
Answer: D
Explanation:
Amazon RDS Proxy is designed to manage a large number of database connections from applications, especially serverless applications that can scale quickly. It improves application availability and scalability by pooling and sharing established database connections. This reduces the overhead of database connections and prevents overload during traffic spikes.
Reference: AWS Documentation - Amazon RDS Proxy
NEW QUESTION # 472
[Design Resilient Architectures]
A software company needs to upgrade a critical web application. The application is hosted in a public subnet. The EC2 instance runs a MySQL database. The application's DNS records are published in an Amazon Route 53 zone.
A solutions architect must reconfigure the application to be scalable and highly available. The solutions architect must also reduce MySQL read latency.
Which combination of solutions will meet these requirements? (Select TWO.)
- A. Migrate the database to an Amazon Aurora MySQL cluster. Create the primary DB instance and reader DB instance in separate Availability Zones.
- B. Launch a second EC2 instance in a second AWS Region. Use a Route 53 failover routing policy to redirect the traffic to the second EC2 instance.
- C. Migrate the database to an Amazon Aurora MySQL cluster with cross-Region read replicas.
- D. Create and configure an Auto Scaling group to launch private EC2 instances in multiple AWS Regions. Add the instances to a target group behind a new Application Load Balancer.
- E. Create and configure an Auto Scaling group to launch private EC2 instances in multiple Availability Zones. Add the instances to a target group behind a new Application Load Balancer.
Answer: A,E
Explanation:
To improve scalability and availability, EC2 Auto Scaling across multiple Availability Zones with an Application Load Balancer ensures resilient infrastructure. Migrating to Amazon Aurora MySQL with reader endpoints reduces read latency by offloading read traffic to replicas in otherAZs, while also increasing high availability.
NEW QUESTION # 473
[Design Resilient Architectures]
A company is migrating a document management application to AWS. The application runs on Linux servers. The company will migrate the application to Amazon EC2 instances in an Auto Scaling group. The company stores 7 TiB of documents in a shared storage file system. An external relational database tracks the documents.
Documents are stored once and can be retrieved multiple times for reference at any time. The company cannot modify the application during the migration. The storage solution must be highly available and must support scaling over time.
Which solution will meet these requirements MOST cost-effectively?
- A. Create an Amazon S3 bucket that uses the S3 Standard-Infrequent Access (S3 Standard-IA) storage class Mount the S3 bucket on the EC2 instances in theAuto Scaling group.
- B. Deploy an SFTP server endpoint by using AWS Transfer for SFTP and an Amazon S3 bucket. Configure the EC2 instances in the Auto Scaling group toconnect to the SFTP server.
- C. Create an Amazon.. System (Amazon fcFS) file system with mount points in multiple Availability Zones. Use the bFS Stondard-intrcqucnt Access (Standard-IA) storage class. Mount the NFS share on the EC2 instances in the Auto Scaling group.
- D. Deploy an EC2 instance with enhanced networking as a shared NFS storage system. Export the NFS share. Mount the NFS share on the EC2 instances in theAuto Scaling group.
Answer: C
Explanation:
Requirement Analysis: The company needs highly available, scalable storage for a document management application without modifying the application during migration.
EFS Overview: Amazon EFS provides scalable file storage that can be mounted concurrently on multiple EC2 instances across different Availability Zones.
EFS Standard-IA: Using the Standard-IA storage class helps reduce costs for infrequently accessed data while maintaining high availability and scalability.
Implementation:
Create an EFS file system.
Configure mount targets in multiple Availability Zones to ensure high availability.
Mount the EFS file system on EC2 instances in the Auto Scaling group.
Conclusion: This solution meets the high availability, scalability, and cost-effectiveness requirements without needing application modifications.
Reference
Amazon EFS:Amazon EFS Documentation
EFS Storage Classes:Amazon EFS Storage Classes
NEW QUESTION # 474
A company is storing its financial reports and regulatory documents in an Amazon S3 bucket. To comply with the IT audit, they tasked their Solutions Architect to track all new objects added to the bucket as well as the removed ones. It should also track whether a versioned object is permanently deleted. The Architect must configure Amazon S3 to publish notifications for these events to a queue for post- processing and to an Amazon SNS topic that will notify the Operations team.
Which of the following is the MOST suitable solution that the Architect should implement?
- A. Create a new Amazon SNS topic and Amazon SQS queue. Add an S3 event notification configuration on the bucket to publish s3:ObjectCreated:* and ObjectRemoved:DeleteMarkerCreated event types to SQS and SNS.
- B. Create a new Amazon SNS topic and Amazon SQS queue. Add an S3 event notification configuration on the bucket to publish s3:ObjectCreated:* and s3:ObjectRemoved:Delete event types to SQS and SNS.
- C. Create a new Amazon SNS topic and Amazon MQ. Add an S3 event notification configuration on the bucket to publish s3:ObjectAdded:* and s3:ObjectRemoved:* event types to SQS and SNS.
- D. Create a new Amazon SNS topic and Amazon MQ. Add an S3 event notification configuration on the bucket to publish s3:ObjectCreated:* and ObjectRemoved:DeleteMarkerCreated event types to SQS and SNS.
Answer: B
Explanation:
The Amazon S3 notification feature enables you to receive notifications when certain events happen in your bucket. To enable notifications, you must first add a notification configuration that identifies the events you want Amazon S3 to publish and the destinations where you want Amazon S3 to send the notifications. You store this configuration in the notification subresource that is associated with a bucket.
Amazon S3 provides an API for you to manage this subresource.
Amazon S3 event notifications typically deliver events in seconds but can sometimes take a minute or longer. If two writes are made to a single non-versioned object at the same time, it is possible that only a single event notification will be sent. If you want to ensure that an event notification is sent for every successful write, you can enable versioning on your bucket. With versioning, every successful write will create a new version of your object and will also send an event notification.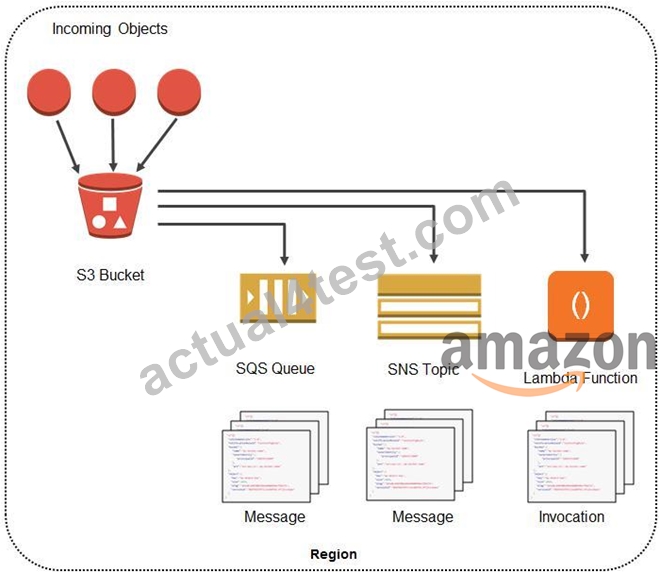
Amazon S3 can publish notifications for the following events:
1. New object created events
2. Object removal events
3. Restore object events
4. Reduced Redundancy Storage (RRS) object lost events
5. Replication events

Amazon S3 supports the following destinations where it can publish events:
1. Amazon Simple Notification Service (Amazon SNS) topic
2. Amazon Simple Queue Service (Amazon SQS) queue
3. AWS Lambda
If your notification ends up writing to the bucket that triggers the notification, this could cause an execution loop. For example, if the bucket triggers a Lambda function each time an object is uploaded and the function uploads an object to the bucket, then the function indirectly triggers itself. To avoid this, use two buckets, or configure the trigger to only apply to a prefix used for incoming objects.
Hence, the correct answers is: Create a new Amazon SNS topic and Amazon SQS queue. Add an S3 event notification configuration on the bucket to publish s3:ObjectCreated:* and s3:ObjectRemoved:Delete event types to SQS and SNS.
The option that says: Create a new Amazon SNS topic and Amazon MQ. Add an S3 event notification configuration on the bucket to publish s3:ObjectAdded:* and s3:ObjectRemoved:* event types to SQS and SNS is incorrect. There is no s3:ObjectAdded:* type in Amazon S3. You should add an S3 event notification configuration on the bucket to publish events of the s3:ObjectCreated:* type instead.
Moreover, Amazon S3 does support Amazon MQ as a destination to publish events.
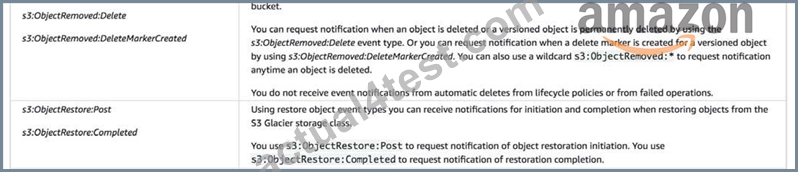
The option that says: Create a new Amazon SNS topic and Amazon SQS queue. Add an S3 event notification configuration on the bucket to publish s3:ObjectCreated:* and ObjectRemoved:DeleteMarkerCreated event types to SQS and SNS is incorrect because the s3:ObjectRemoved:DeleteMarkerCreated type is only triggered when a delete marker is created for a versioned object and not when an object is deleted or a versioned object is permanently deleted.
The option that says: Create a new Amazon SNS topic and Amazon MQ. Add an S3 event notification configuration on the bucket to publish s3:ObjectCreated:* and ObjectRemoved:DeleteMarkerCreated event types to SQS and SNS is incorrect because Amazon S3 does public event messages to Amazon MQ. You should use an Amazon SQS instead. In addition, the s3:ObjectRemoved:DeleteMarkerCreated type is only triggered when a delete marker is created for a versioned object. Remember that the scenario asked to publish events when an object is deleted or a versioned object is permanently deleted.
References:
https://docs.aws.amazon.com/AmazonS3/latest/dev/NotificationHowTo.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/ways-to-add-notification-config-to-bucket.html
https://aws.amazon.com/blogs/aws/s3-event-notification/
Check out this Amazon S3 Cheat Sheet:
https://tutorialsdojo.com/amazon-s3/
Amazon SNS Overview:
https://www.youtube.com/watch?v=ft5R45lEUJ8
NEW QUESTION # 475
A company has developed an API by using an Amazon API Gateway REST API and AWS Lambda functions. The API serves static content and dynamic content to users worldwide. The company wants to decrease the latency of transferring the content for API requests. Which solution will meet these requirements?
- A. Deploy the REST API as an edge-optimized API endpoint. Enable caching. Configure reserved concurrency for the Lambda functions.
- B. Deploy the REST API as a Regional API endpoint. Enable caching. Configure reserved concurrency for the Lambda functions.
- C. Deploy the REST API as an edge-optimized API endpoint. Enable caching. Enable content encoding in the API definition to compress the application data in transit.
- D. Deploy the REST API as a Regional API endpoint. Enable caching. Enable content encoding in the API definition to compress the application data in transit.
Answer: C
Explanation:
* Edge-Optimized API: Designed for global users by routing requests through CloudFront's edge locations, reducing latency.
* Content Encoding: Enabling content encoding compresses data, further optimizing performance by decreasing payload size.
* Caching: Adding API Gateway caching reduces the number of calls to Lambda and database backends, improving latency.
* Reserved Concurrency: Although useful, this does not directly affect latency for transferring static and dynamic content.: AWS API Gateway Edge-Optimized APIs Documentation
NEW QUESTION # 476
A company wants to build a scalable key management Infrastructure to support developers who need to encrypt data in their applications.
What should a solutions architect do to reduce the operational burden?
- A. Use AWS Key Management Service (AWS KMS) to protect the encryption keys
- B. Use multifactor authentication (MFA) to protect the encryption keys.
- C. Use AWS Certificate Manager (ACM) to create, store, and assign the encryption keys
- D. Use an IAM policy to limit the scope of users who have access permissions to protect the encryption keys
Answer: A
Explanation:
https://aws.amazon.com/kms/faqs/#:~:text=If%20you%20are%20a%20developer%20who%20needs%20to%20digitally,a%20broad%20set%20of%20industry%20and%20regional%20compliance%20regimes.
NEW QUESTION # 477
[Design Secure Architectures]
A company has a small Python application that processes JSON documents and outputs the results to an on-premises SQL database. The application runs thousands of times each day. The company wants to move the application to the AWS Cloud. The company needs a highly available solution that maximizes scalability and minimizes operational overhead.
Which solution will meet these requirements?
- A. Place the JSON documents in an Amazon S3 bucket. Run the Python code on multiple Amazon EC2 instances to process the documents. Store the results in an Amazon Aurora DB cluster
- B. Place the JSON documents in an Amazon Elastic Block Store (Amazon EBS) volume. Use the EBS Multi-Attach feature to attach the volume to multiple Amazon EC2 instances. Run the Python code on the EC2 instances to process the documents. Store the results on an Amazon RDS DB instance.
- C. Place the JSON documents in an Amazon Simple Queue Service (Amazon SQS) queue as messages Deploy the Python code as a container on an Amazon Elastic Container Service (Amazon ECS) cluster that is configured with the Amazon EC2 launch type. Use the container to process the SQS messages. Store the results on an Amazon RDS DB instance.
- D. Place the JSON documents in an Amazon S3 bucket. Create an AWS Lambda function that runs the Python code to process the documents as they arrive in the S3 bucket. Store the results in an Amazon Aurora DB cluster.
Answer: D
Explanation:
By placing the JSON documents in an S3 bucket, the documents will be stored in a highly durable and scalable object storage service. The use of AWS Lambda allows the company to run their Python code to process the documents as they arrive in the S3 bucket without having to worry about the underlying infrastructure. This also allows for horizontal scalability, as AWS Lambda will automatically scale the number of instances of the function based on the incoming rate of requests. The results can be stored in an Amazon Aurora DB cluster, which is a fully-managed, high-performance database service that is compatible with MySQL and PostgreSQL. This will provide the necessary durability and scalability for the results of the processing.
https://aws.amazon.com/rds/aurora/
NEW QUESTION # 478
A company stores sensitive data in Amazon S3 A solutions architect needs to create an encryption solution The company needs to fully control the ability of users to create, rotate, and disable encryption keys with minimal effort for any data that must be encrypted.
Which solution will meet these requirements?
- A. Download S3 objects to an Amazon EC2 instance. Encrypt the objects by using customer managed keys.Upload the encrypted objects back into Amazon S3.
- B. Use default server-side encryption with Amazon S3 managed encryption keys (SSE-S3) to store the sensitive data
- C. Create a customer managed key by using AWS Key Management Service (AWS KMS). Use the new key to encrypt the S3 objects by using server-side encryption with AWS KMS keys (SSE-KMS).
- D. Create an AWS managed key by using AWS Key Management Service {AWS KMS) Use the new key to encrypt the S3 objects by using server-side encryption with AWS KMS keys (SSE-KMS).
Answer: C
Explanation:
* Understanding the Requirement: The company needs to control the creation, rotation, and disabling of encryption keys for data stored in S3 with minimal effort.
* Analysis of Options:
* SSE-S3: Provides server-side encryption using S3 managed keys but does not offer full control over key management.
* Customer managed key with AWS KMS (SSE-KMS): Allows the company to fully control key creation, rotation, and disabling, providing a high level of security and compliance.
* AWS managed key with AWS KMS (SSE-KMS): While it provides some control, it does not offer the same level of granularity as customer-managed keys.
* EC2 instance encryption and re-upload: This approach is operationally intensive and does not leverage AWS managed services for efficient key management.
* Best Solution:
* Customer managed key with AWS KMS (SSE-KMS): This solution meets the requirement for full control over encryption keys with minimal operational overhead, leveraging AWS managed services for secure key management.
References:
* AWS Key Management Service (KMS)
* Amazon S3 Encryption
NEW QUESTION # 479
A company website hosted on Amazon EC2 instances processes classified data stored in The application writes data to Amazon Elastic Block Store (Amazon EBS) volumes The company needs to ensure that all data that is written to the EBS volumes is encrypted at rest.
Which solution will meet this requirement?
- A. Create an EC2 instance tag that has a key of Encrypt and a value of True Tag all instances that require encryption at the EBS level
- B. Create an 1AM role that specifies EBS encryption Attach the role to the EC2 instances
- C. Create an AWS Key Management Service (AWS KMS) key policy that enforces EBS encryption in the account Ensure that the key policy is active
- D. Create the EBS volumes as encrypted volumes Attach the EBS volumes to the EC2 instances
Answer: D
Explanation:
The simplest and most effective way to ensure that all data that is written to the EBS volumes is encrypted at rest is to create the EBS volumes as encrypted volumes. You can do this by selecting the encryption option when you create a new EBS volume, or by copying an existing unencrypted volume to a new encrypted volume. You can also specify the AWS KMS key that you want to use for encryption, or use the default AWS-managed key. When you attach the encrypted EBS volumes to the EC2 instances, the data will be automatically encrypted and decrypted by the EC2 host. This solution does not require any additional IAM roles, tags, or policies.
References:
Amazon EBS encryption
Creating an encrypted EBS volume
Encrypting an unencrypted EBS volume
NEW QUESTION # 480
A company has a web application that is based on Java and PHP The company plans to move the application from on premises to AWS The company needs the ability to test new site features frequently. The company also needs a highly available and managed solution that requires minimum operational overhead Which solution will meet these requirements?
- A. Deploy the web application to an AWS Elastic Beanstalk environment Use URL swapping to switch between multiple Elastic Beanstalk environments for feature testing
- B. Deploy the web application lo Amazon EC2 instances that are configured with Java and PHP Use Auto Scaling groups and an Application Load Balancer to manage the website's availability
- C. Containerize the web application Deploy the web application to Amazon EC2 instances Use the AWS Load Balancer Controller to dynamically route traffic between containers thai contain the new site features for testing
- D. Create an Amazon S3 bucket Enable static web hosting on the S3 bucket Upload the static content to the S3 bucket Use AWS Lambda to process all dynamic content
Answer: A
Explanation:
Explanation
Frequent feature testing -
- Multiple Elastic Beanstalk environments can be created easily for development, testing and production use cases.
- Traffic can be routed between environments for A/B testing and feature iteration using simple URL swapping techniques. No complex routing rules or infrastructure changes required.
NEW QUESTION # 481
A solutions architect needs to optimize a large data analytics job that runs on an Amazon EMR cluster. The job takes 13 hours to finish. The cluster has multiple core nodes and worker nodes deployed on large, compute-optimized instances.
After reviewing EMR logs, the solutions architect discovers that several nodes are idle for more than 5 hours while the job is running. The solutions architect needs to optimize cluster performance.
Which solution will meet this requirement MOST cost-effectively?
- A. Migrate the analytics job to a set of AWS Lambda functions. Configure reserved concurrency for the functions.
- B. Increase the number of core nodes to ensure there is enough processing power to handle the analytics job without any idle time.
- C. Use the EMR managed scaling feature to automatically resize the cluster based on workload.
- D. Migrate the analytics job core nodes to a memory-optimized instance type to reduce the total job runtime.
Answer: C
Explanation:
EMR managed scaling dynamically resizes the cluster by adding or removing nodes based on the workload.
This feature helps minimize idle time and reduces costs by scaling the cluster to meet processing demands efficiently.
* Option A: Increasing the number of core nodes might increase idle time further, as it does not address the root cause of underutilization.
* Option C: Migrating the job to Lambda is infeasible for large analytics jobs due to resource and runtime constraints.
* Option D: Changing to memory-optimized instances may not necessarily reduce idle time or optimize costs.
AWS Documentation References:
* EMR Managed Scaling
NEW QUESTION # 482
......
2025 New Preparation Guide of Amazon SAA-C03 Exam: https://examtorrent.actual4test.com/SAA-C03_examcollection.html